EDI Configurator
Contents
Description
For some of the more common EDI formats (CSV, XLS, XLSX and XML) the user is able to tell cargooffice how to parse an EDI file. Below is a description of this program. It can be found here:
Backoffice -> Shipments -> EDI Configurator
A note on spreadsheet files : If these are Microsoft spreadsheets containing formulas then the results might be unpredictable do to Microsofts proprietary formats of the fomulas. You have to test these files thoroughly before entering production or use an open standard.
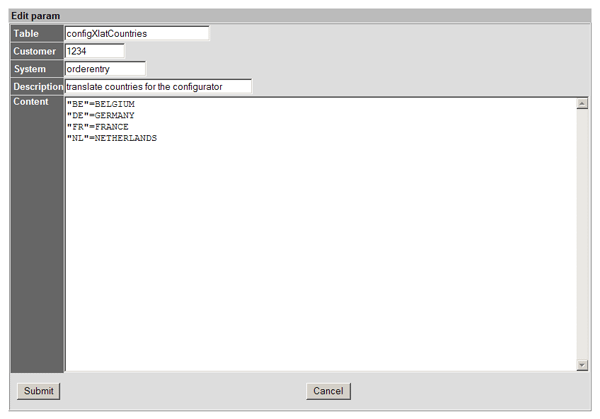
Example screen
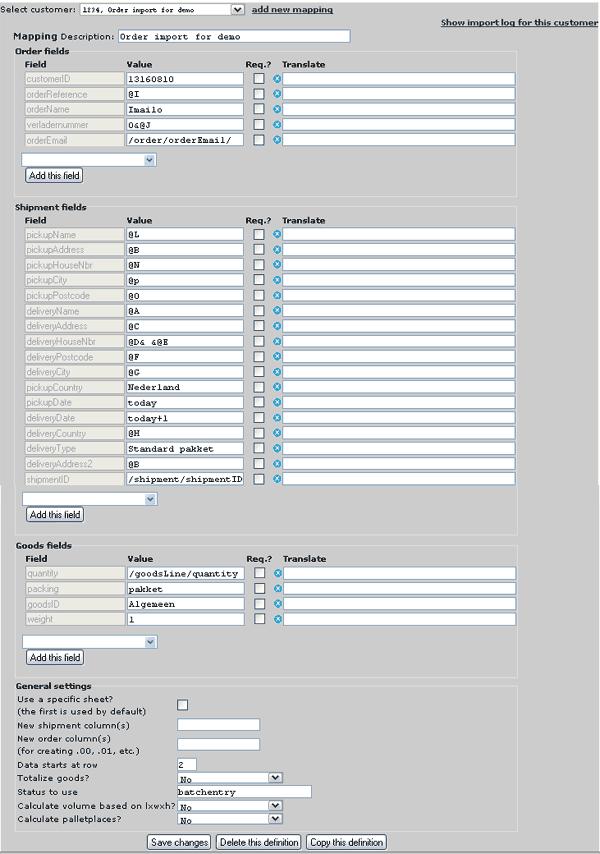
This is an example of a configuration screen, an explanation follows.

Enter a new configuration or choose an existing one
Click
add new mapping if you want to enter a new configuration. The system will ask you for a customer number, each time this customer sends and EDI file, this new configuration is used to import the data.
Alternatively you can choose an existing customer to make changes to it's configuration.
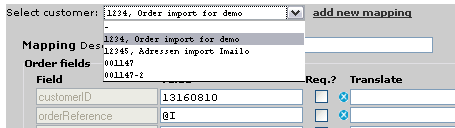
Mapping of cargooffice fields
There are three sections where you can map cargooffice fields to input data; the
order,
shipment and
goods section. Generally an
order in cargooffice has one or more
shipments, and a shipment may have one or more
goods (lines).
To add a field, choose the relevant cargooffice fieldname from the list and click
Add this field:
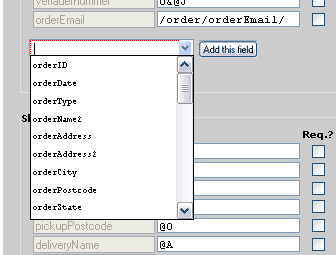
Use parameter goodsFieldNames, shipFieldNames or orderFieldNames if you want to add a not listed field.
A literal value
The
value column may contain a literal, a fixed value that will allways be loaded into the selected cargooffice field. In the example screen at the top of this page the literal
13160810 is loaded into field
customerID. And the literal
Imailo is loaded into field
orderName.
column references (csv and xls)
By using @ you can reference columns in a spreadsheet (.xls files) and also columns in a csv file. In latter case (a csv file) @A means the first column, @B the second column etc.

field references
The
value column may contain a reference to a field. The field must be defined earlier in the configuration and its name must be between curly brackets. Example:
 Note:
Note: in this example
orderReference must be defined earlier in the configuration (upstream).
Note: referencing a field can not be combined with concatenate function
XML tag references
By using / you can reference tags in an xml file. The reference is an xpath like reference where you need to specify both the group tag name as well as the tag name itself. For example
/order/orderEmail references the tag <orderEmail> within the group tag <order>. There is no need to reference any higher levels in the xml, the system only needs the group tag names for the
order,
shipment and
goods (lines).
For an example XML have a look at:
LPtransXml
 Note1:
Note1: You have to specify any lower levels in xpath definitions. If for example you want to reference <packingType> in the following xml, you will use: /goodsLine/packingDetails/packingType.
<exampleXml>
<order>
..
<shipment>
..
<goodsLine>
<packingDetails>
<packingType>container</packingType>
<packingSize>20ft</packingSize>
</packingDetails>
</goodsLine>
..
Note2: The xpath definition always starts with the repeating group tag, in this example /goodsLine/ because this tag repeats itself within a shipment. In the same fashion references to shipment tags begin with /shipment/ and references to order tags begin with /order/. So always the repeating group tag first, and no higher levels.
Note3: To help the system finding the order-shipment-goodsLine hierarchy, please enter some fieldNames (tags) from each hierarchy into the params
orderFieldnames,
shipmentFieldNames and
goodsFieldnames.
WARNING:If not one tag of the XML can be found in these params then the file might not be processed.
Note4: It is possible to use
regular expressions in the xpath definitions. This might be useful if you need an xml tag with a specific attribute. If for example you need the vessel name from the xml below, you might use the following definition:

<exampleXml>
<order>
..
<shipment>
<vesselDetails>
<ident type="vesselType">bulk carrier</ident>
<ident type="vesselName">Joyride</ident>
<ident type="vesselLength">130</ident>
</vesselDetails>
..
Note5: An easier method of getting an attribute is using the '@' character:
 Note6:
Note6: The system uses a
subset of the xpath syntax. You can use the "real" xpath syntax if you need more complex definitions. In this case you
must begin the definition with a double slash (//),
Some examples:
- //consignment/location[qualifier="OS"]/address
- //transportInstruction/consignment/../datetime
- //consignment/location[2]/name
Remark1: For more information and examples see:
this page Remark2:
Remark2: You can test your xpath definitions:
here
Remark3: If your "real" xpath doesn't work, then try to define the complete path, so with all higher levels.
Trick: x-paths are only recognised if the first character in the 'value' field is '/'. It is not possible to concatenate an x-path with a leading text like 'Location:& &//consignment/location[qualifier="OS"]/address'.
What you can do to circumvent this is use a non-existing x-path as your first x-path. Like '//consigment/loc&Location:& &//consignment/location[qualifier="OS"]/address'.
You will trick the configurator into recognising the x-path, the first x-path will evaluate to nothing and effectively the result will have your leading text. Neat, huh?
Remark4: You can use ../ ("real" xpath only!) to go to a higher level of your xml file BUT you can only go as high as the highest level you have used in the configuration. For example:
<exampleXml>
<order>
<orderReference>123</reference>
<shipment>
<vesselDetails>
<ident type="vesselType">bulk carrier</ident>
<ident type="vesselName">Joyride</ident>
<ident type="vesselLength">130</ident>
</vesselDetails>
</shipment>
<shipment>
....
<shipment>
if you want to reach the orderReference, you could use //vesselDetails/../../orderReference but you can only do so if your starting point in the configuration was //order or higher.
Warning: Using the "real" xpath syntax might be slower than using the default subset.
Partial value: substring
Notation: @{column}:substr(int $start [, int $length ])
Substr takes a specific part of a value, defined by the
start en
length parameters. If
start is positive, the resulting value is the part starting from this position to the end of the value, counting from zero. For example in string 'abcdef', the character at position 0 is 'a' and the character at position 2 is 'c', etc.
Substr examples:
Where column @A has a value of '1234':
- @A:substr(1) results in `234`
- @A:substr(1, 2) results in `23`
- @A:substr(0, 4) results in `1234`
If
start is negative, the result will start at the position counting from the end of the value, for example:
Where column @A has a value of '1234':
- @A:substr(-1) results in `4`
- @A:substr(-2) results in `34`
- @A:substr(-3, 1) results in `2`
Concatenate values
By using & multiple references can be concatenated into one cargooffice field. Like these examples:
 customerID
customerID : If column B has the value `1234` then the resulting value in field customerID will be `customer1234`
orderReference : If column I has a value 'ref' and J 'abc' then the resulting value in field orderRefenece will be 'ref abc'.
Split values
Notation: @{column}:split(string $separation, int $position)
This function splits a value into 1 or more parts where parameter
$separation defines the character or string on which the value is split and parameter
$position defines which part should be taken.
Examples:
Where column @A has a value of `10:00 12:00`:
- @A:split("", 0) results in `10:00`
- @A:split("", 1) results in `12:00`
Dates
In general dates must be defined in the format YYYY-MM-DD, or (in spreadsheets) defined as a date formatted column.
The special function
today takes the current date plus a number of days. Example:
Normally
workdays are standard, skipping weekends, as if you wrote today+1workday .
If you don't want workdays and include weekends then add the text days to the number. Example:
Alternatively you can also use
pickupDate+n. In this case the pick-up date is used plus an optional number of days. For example:
Please note:
- in this case pickupDate must be defined first before you can refer to it.
Also (less common) you can use
deliveryDate-n. In this case the deliveryDate is used minus an optional number of days. For example:
If your input date has another format you can use the
Translate column to reformat it.
In the example below we use the
preg_replace function to translate a dd-mm-yyyy formatted date into yyyy-mm-dd:
Also see the description about the
Translate column below.
Please note:
- weekends are normally skipped. So if today+1 is a Saturday or a Sunday, Monday will be used (except when you write 'today+1day' like example 2 above, then weekends are skipped).
- this also applies to the deliveryDate-1 option, when deliveryDate is a Monday, deliveryDate-1 will be the Friday before.
- just 'today' will not work; you have to use 'today+0' when referring to today or any other date.
- only fields with a fieldname ending with 'Date' can be used to store values using the today+n, pickupDate+n or deliveryDate-n options. Other fields that you use this option on will show the actual text 'today+n' in them.
- 'Zero' date is Unix Epoch or 01-01-1970. Should you run into problems and receive date values in 1969 or 1970, you are probably using a base date value of 0.
Simple Arithmetic
You can do simple arithmetic by starting a column reference with a plus (+) sign. Example:
Here three columns are multiplied by each other (i.e lenght, width and height) to get the volume.
Examples:
- +@L/100*@W*@H
- +@L*(@W + 2)*@H
- +round(@L * @W * @H,2)
NOTE: You cannot combine arithmetic with xml paths. There is a way around this. The xml is converted to a csv which can be viewed when you use the 'test' button on the bottom right of the configurator screen. You can then use the columns of this csv for calculations. If you place new variables/fields
above this column reference, you will need to check and re-define the column reference.
This may look like this:

Translate column
The translate column is used to translate values into other values or for some special functions (described below).
Translate values are separated by commas and the original value (the first value) is separated by the target value by =. Example:
In the example above various delivery terms are translated into numeric values.
NOTE: You can add a
default value by using an asterisk character
(*)
. For example
*=000, will translate unknown values into 000.
Literals: By using double quotes you determine that the matching value must be an exact
literal. In other words, the whole value must match (without double quotes BEER would be translated into BelgieER).
A literal match is case insensitive.
Regular expression: By using forward slashes you determine that the matching value is a
regular expression. In this case any value matching the expression is translated. Please note that the comparison is always
case insensitive.
To match an
empty value you can use /^$/=... (example: to translate an empty value for quantity to 1, use: /^$/=1).
note: The examples above can be combined. So any combination of translations with quotes, without quotes and regular expressions may me used in the same translation line.
Multi column definitions
Sometimes a CSV or XLS file contains multiple columns for quantity.
Example:
| A |
B |
C |
D |
E |
F |
G |
| orderID |
From |
To |
Pallets |
Boxes |
Colli |
Crates |
| 12345 |
London |
Paris |
|
2 |
|
|
| 12346 |
Brimingham |
Southampton |
|
|
|
4 |
| 12347 |
Glasgow |
Amsterdam |
1 |
3 |
|
|
For order 12345 one goods line is requested for 2 boxes.
For order 12346 one goods line is requested for 4 crates.
For order 12347
two goods lines are requested, one goods line with 1 pallet and another goods line with 3 boxes.
To define this you can use the -or- character | (a vertical bar) between the column definitions.
Example:
Also look at the second line for
packing, here the value is translated into a text.
The question mark means: if there is a value in this column then translate it.
NOTE If the packing name is in a column you can also use a column definition here. For example:
@D?=@H,@E?=@I,@F?=@J,@G?=@K
Function: param:
The function
param: retrieves the translate values from a parameter. Example:
The parameter must be defined in the
orderEntry parameters.
Example:
notes:
- The parameter may also contain any of the functions described below, although it is intended for large code- or translation tables.
- If the from value is between double quotes (") the matching value is a literal, meaning that for instance "BE" will not match with BELGIUM, but only with BE.
- If the from value is not between quotes a partial replacement may take place. For instance in the example above BEER would be translated into BELGIUMER.
- Matching of a literal (between double quotes) is case insensitive, in all other cases it is case-sensitive.
- If the from value is between forward slashes (/) the matching value is a regular expression, meaning that for instance /B.*GIUM/ will match with BELGIUM. Reglular expressions are always case insensitive here.
- See also the paragraph on Translate column above.
Function: preg_match
The
preg_match function is an alternative method to take specific part from a value. It is meant for more experienced users, for example programmers who know what
regular expressions are, more specific perl compatible regular expressions .
preg_match matches the value with a certain regular expression and picks out the part defined between parentheses.
The
preg_match must be entered into the
translate column, for example:
This regular expression matches an address that looks like a street name together with a house number. It filters out the house number and only takes the street name, the part between parentheses (.*).
Function: preg_replace
The
preg_replace function is an alternative method to do translations. It is meant for more experienced users, for example programmers who know what
regular expressions are, more specific perl compatible regular expressions .
preg_replace matches parts of a value with a certain regular expression and replaces those parts by a second value.
The
preg_replace must be entered into the
translate column, for example:
In this example the string ',000' or the character '.' (a dot) is replaced by nothing (since the second value in this example, the value between //, is blank).
Backreferencing
preg_replace/(\d{2})(\d{2})(\d{2})(\d{2})/$1-$2-$4/
This function will translate 10102012 into 10-10-12 using backreferences.
Function: toFloat
The function
toFloat translates a string into a
floating point number.
Example:
Function: min
The function
min takes a minimum value. If the column value is less than the given min value then the min value is taken.
Example:
If in this example the value of column AC is less than 1 then 1 is filled in into field palletPlaces.
Function: ceil
The function
ceil rounds fractions up to the next whole (integer) number.
Example:
If in this example the value of column AC is 31.2 then 32 is filled in into field quantity.
Function: condition
The function
condition compares two values and depending on the result takes either the true-value or the false-value.
Example:
If in this example the value of column G greater than 0 then "pallet" is filled in into field packing. If not then "colli" is filled in into field packing.
The column that should be evaluated must be in the 'value' (waarde) field, in this example :
@G.
Other examples:
- condition(@G > 0)? @G : @H if column G is greater than zero then the value of column G is taken, else the value of column H.
- condition(@F >= 12:00)? "afternoon" : "morning" if column F is greater or equal to 12:00 then "afternoon" is taken, else "morning".
- condition(@F <= 10 )? @A".00kg" : @B"m3" if column F is less or equal to 10 then the value of column A is taken plus an extra string ".00kg", else the value of column B is taken plus an extra string "m3".
- condition(@F == "text string")? "true":"false" if the operand that is tested upon is an alphanumeric, the value tested for must also be enclosed in double quotes!!! DO NOT USE SINGLE QUOTES!
- condition(@F == "text string")? @X : "or else" a combination of litteral text and column references can be made. Texts go inside double quotes, references do not.
NOTE : please beware that comparing against an empty column may cause unexpected results.
NOTE : Instead of a column definition (e.g. @A) it is also possible to use a field name, like:
{customerID}. The field name must be between curly brackets and defined earlier in the configuration. Example:
- condition({pallets} > 0)? {pallets} : {colli} if the content of field pallets is greater than zero then the value of pallets is taken, otherwise the value of field colli. Please note that both fields -pallet and colli- must be defined earlier in the configuration (must already have a value).
NOTE on regular expression when using a tilde (~) a
regular expression is performed on the first operand. The regular expression must be between slashes (//). Example:
- condition(@F ~ /KG|Kilo/ )? "kilograms" : "tons" if somewhere in column F the text KG or Kilo is found then the string "kilograms" is taken, else the string "tons".
These methods can be combined like this
- condition({orderReference} ~ /^(2|7|8)/)? "2 (Import)" : "1 (Export)" if field orderReference starts with 2, 7 or 8, the string "2 (Import)" is used, else the string "1 (Export)".
- condition({pickupTimeReqStart} ~ /./)? {pickupTimeReqStart} : "00:00" if field pickupTimeReqStart holds a (any) value, field pickupTimeReqStart is used, else string "00:00". BEWARE that time values (with : in them) can only be used AFTER the separation mark.
Possible comparison operators:
- == Equal
- != Not equal (text)
- <> Not equal (number)
- < Less than
- > Greater than
- <= Less than or equal to
- >= Greater than or equal to
- ~ Regular expression
Special function
Sometimes our programmers create special translation functions for specific clients.
These functions can be called by their name followed by an optional number of parameters.
The programmer will tell you the exact name of the function.
Example:
If in this example a specially created function
calcDeliveryDate() is called together with the values of a number of columns.
The value in column
Value must be a column definition and acts as a default value in this case.
NOTE1 : In stead of a column definition (e.g. @A) it is also possible to use a field name here, like:
{customerID}. The field name must be between curly brackets and defined earlier in the configuration. See also the note on field names in the description above at Function: condition.
NOTE2 : In stead of a column definition (e.g. @A) it is also possible to use a literal, like :
Kilo or
69. Any literals should not be defined between quotes.
Please contact our development department if you need special functions.
Filter trick
Depending on the file set-up there is an option to filter certain record-lines out of your file.
- First you create a condition, that creates empty values.
See example below: condition(@M=="FR")? "FR" : ""
- Then you activate the Req.?-box, defining that only record lines with non-empty values will be parsed.
- Result of this example: only recorld lines from your CSV/XLS file, where FR is set in column M, will be parsed.
Special field "orderID"
Special field
orderID needs some extra explanation.
- If there is no orderID in the input file then cargooffice generates a unique orderID.
- If there is an orderID in the input file and the order already exists, then that order is updated with the data from the input file. Otherwise a new order with that ID is created.
- In stead of orderID you can also use shipmentID. Both field names are synonyms.
- In stead of orderID you can also use trackingNbr. This also uniquely identifies each individual shipment. The format is {CN}.{shipmentID}. (CN = carrier number, a unique number for each carrier using cargooffice).
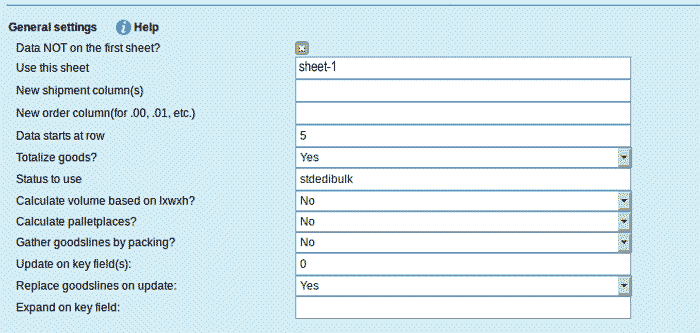
General settings
The general settings can be found below the field mappings.
- Use a specific sheet (.xls files). When using an Excel (.xls) and the data is not on the first sheet, then select Yes and enter the sheet number where the data is.
- New shipment column(s) (.csv and .xls files). Multiple lines in the same input file may belong to the same shipment. Generally to add goods lines to the same shipment. If this column changes then a new shipment is created. For instance a customer reference number, lines with the same customer reference number belong to the same shipment. If you leave this field empty, every line will be written into a new shipment.
- Note: lines with the same data (name, address, postcode, city, country) are normally combined into one shipment with multiple goodslines. This setting may be used to split these goodsLines into multiple shipments too.
- Note: it is possible to combine multiple columns for this function like this: @B&@O
- Note: cannot be used when converting XML files!
- New order column(s) (.csv and .xls files). An order may consist of multiple shipments. Since each shipment is on a separate line there must be a reference column to tell the program which lines belong to the same order. Mostly an order reference number. Cargooffice will use the orderID as a basis for each shipmentID and expands it with a sequence number .00, .01, .02 etc.
- If you need the whole file to be put in one order but there is no suitable reference column, you can put a non-existing column in this field. The value of this column will (as it does not exist) always evaluate to the same and therefore all shipments in the file will be combined into one order.
- Note: it is possible to combine multiple columns for this function like this: @B&@O
- Note: cannot be used when converting XML files!
- Data starts at row (.csv and .xls files). Most input files contain one or more header lines indicating what values are in which columns. The actual data starts in row 2 or later. The row number where the data starts must be entered here.
- Totalize goods? (all files). Enter 'Yes' if there is no total quantity in the order. The individual quantities of the goods lines are totalized into a total quantity field. In fact, all numeric fields are totalized; number of pallets, volume, weight etc.
- Status to use (all files). For EDI shipments we advise to use status 'stdedibulk'. This automatically generates an output file for the carrier's own TMS system. If a different status is required, or an output file for the TMS system is not required, a different initial status can be chosen here. A frequently used status here is 'batchentry', meaning that the orders are added to a batch which can be send later.
If you do not want an automatically generated output or not status 'batchentry', then we advise to choose one of our other default statuses.
- Note: it is also possible to set the 'status' field in the field mappings, if the status needs to depend on a value in the incoming file. This is useful when creating/updating a shipment where you may want to set 'stdedibulk' for new shipments and 'orderchange' for updates. If you map the status field in the field mappings, leave the 'Status to use' field empty.
- Calculate volume based on lxwxh (all files). Select Yes if you want the volume calculated using the formula length/100 * width/100 * height/100.
WARNING Select No if you use your own formula like the example under Simple Arithmetic.
- Calculate palletplaces (all files). Select Yes if you want the number of pallet places calculated. The program will ask you for the column containing the pallet type and the quantity. The program uses param palletsizes to find the factor by which quantity is multiplied. The format is palletType=factor|description (example below).
Example content for param 'palletsizes' :
EU=1|europallet
BL=1.25|blockpallet
CHEP=1.25|block-cheppallet
EC=1|euro-cheppallet
- Gather goodslines by packing (all files). Select Yes if you want the number of goods lines with the same packing ID to be summed together into one goods line. If for instance there are two goods lines with packing 'pallet' and three goods lines with packing 'box' then just two goods lines will remain, one for 'pallets' and one for 'box'.
- Update on key field(s) (all files). If you want to update an already existing order then specify here the key fields to find the order. If you specify more than one field then separate them by a plus (+) character. For example: orderReference+pickupDate will try to find an already existing order with the same orderReference and pickupDate of the current EDI record. If it exists then it is updated. If it does not exist then a new order is created, as is the case when you leave this setting blank.
NOTE1: field orderReference is always used to update a shipment, so in the example above entering only pickupDate would give the same result as entering orderReference+pickupDate. However, if orderReference is the only field you wish to update on then you have to enter orderReference here to activate the update option.
NOTE2: please be aware that using fieldname refShipmentID here could give unpredictable results. We use that fieldname as an index into the database table. Also be careful not to use fieldname containerNbr anywhere in the configuration, this also could give unpredictable results.
- Replace goodslines on update (all files). If you want to update an already existing order and there is a possibility that the new file contains less goods lines then select Yes. Otherwise old goods lines will remain in the order and you end up with too many goods lines.
- Expand on key field (all files). If you want to expand an already existing order with more shipments then specify the key field to find the already existing order. The order number will get an extension like .00 while the extra added shipments receive extensions like .01, .02, .03 etc.. Please note that the field name you specify here must have more than 5 characters.
--
HenkRoelofs - 2012-02-24

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}